")
How do you know if a gift is actually good when "good" means something different for every user?
We've spent six months building a personalised gift recommendation engine that leverages large language models. Along the way, we've discovered that evaluating whether a personalised product is improving is a fundamentally different challenge from anything the standard playbook covers. This is the first article in How we build. Here's what we've found.
You know that feeling when you give a gift and you just know you've nailed it?
You're watching them open it. There's the surprise. Then the confusion. Then that look: how did you know? How did you even find this?
That feeling only works because of who these two people are to each other, in this moment, in this context. We call it the 'Wow!' moment. The 'Wow!' when you find it. The 'Wow!' when you give it. And the 'Wow!' from the person receiving it. It's what we're building toward at GiftyWow. And the hardest part isn't the technology. It's knowing whether the technology is actually getting better or worse.
The conversation that changed how we think about quality
In one of our regular customer sessions, a mother told us her daughter had compared our gift recommendations to ChatGPT's. The daughter preferred ChatGPT.
Heart-sinking moment.
We asked the mum: and what did you think of ChatGPT's recommendations? She said they were popular. Her daughter liked them. So we asked: would you actually buy them for her?
No.
She wants to buy things that are aspirational for who she sees her daughter becoming. Things that inspire rather than just follow what's trending. Things that won't end up in the bin within a year. She wants gifts that signal to her daughter: I see you, I value you, and I believe in who you're growing into.
So the daughter liked ChatGPT's suggestions. The mum didn't. Both were right. Which raised the question we keep coming back to: who gets to decide what a "good" gift is?
And it gets harder. People can't always articulate what they actually want. One person we spoke with was adamant: too much stuff, don't want anything, very specific taste, don't buy me clothes, no more homewares.
Then we asked what the most memorable gifts she'd received in the past year were. Two answers: a picture for her home and a shirt. Both broke every rule she'd just given us. Both worked because they were deeply personal to her in her context.
You can't just ask people what they want. The rules they give you aren't necessarily true. And you can't evaluate quality from the outside looking in.
The giver-receiver problem
With most products, you're optimising for one user. With gifting, you're optimising for two.
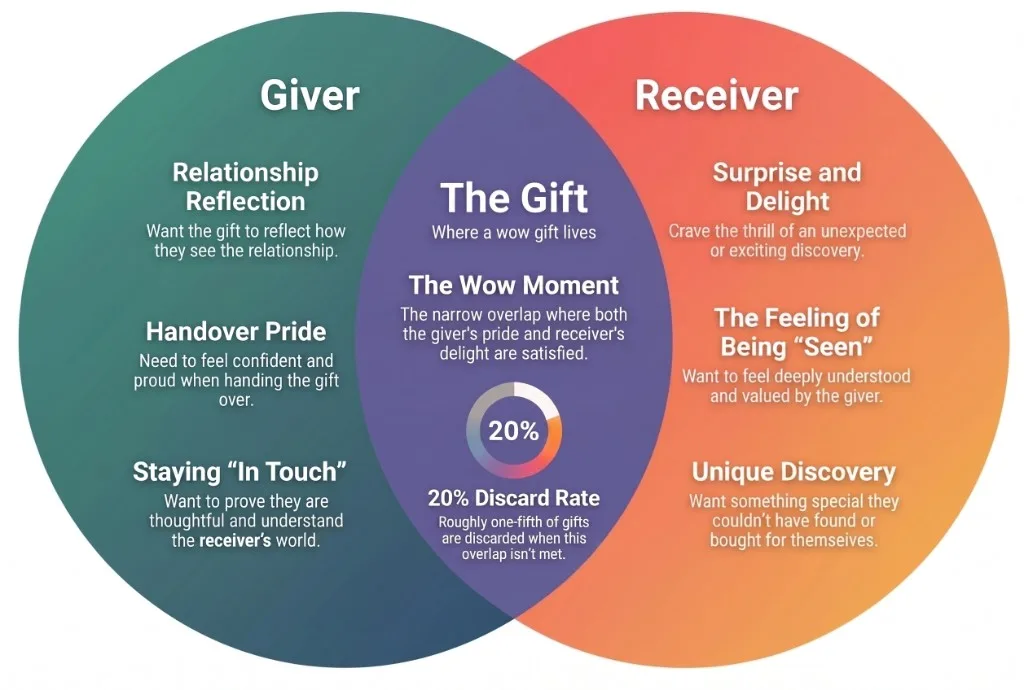
The 'Wow!' moment is where giver pride and receiver delight overlap. Many people miss it, that's why roughly one in five gifts don't land. Why is gifting so hard ?
That mother-and-daughter moment from earlier is a clean example of the giver-receiver problem. They were not arguing about whether gifts matter. They were answering different questions about what "good" means.
| Mum (giver) | Daughter (receiver) | |
|---|---|---|
| What she's optimising for | A gift she feels proud to give: something that lasts, fits who she sees her daughter becoming, and won't end up forgotten in a year | A gift that fits her life right now: surprising, delightful, and legible to her friends |
| What "good" looks like to her | "You see me. You value me. You believe in who I'm growing into." | "You get who I am today, not who you wish I were." |
| What she's reading in the gift | Care, attention, and parental judgement (did I choose something worthy of her?) | Identity and fit (is this me, in my world, right now?) |
| Why ChatGPT split them | Trending picks felt popular but generic. She wouldn't buy them because they didn't carry her signal of care | Trending picks scored on immediate fit and shareability, even if they weren't deeply personal |
| When it goes wrong | She gives something "good for you" and feels thoughtful; her daughter feels managed | She gets something her mum loves but wouldn't choose; the moment lands flat socially |
Neither of them is wrong. They're playing two roles in the same exchange: the giver modelling care and pride, the receiver testing for fit and delight. When those goals don't overlap, gifting fails even with love and budget on the table. Different tastes, ages, and aesthetics make that gap wider, but the real fracture is two definitions of success. That's one reason roughly 20% of gifts are discarded, returned, or regifted. There's a reason for that.
Why standard eval tools aren't built for this
The product community has become obsessed with evals evals Think of them like performance reviews for AI systems. You have criteria for what success looks like. Good criteria help you make consistent judgements and track improvement. Evals do this for AI: structured ways to measure whether output is getting better or worse so you can compare versions. At their core, they answer three questions: is the quality high enough, are the results consistent and reliable, and did this change actually help? , and for good reason. But most of the tooling has grown out of a specific paradigm: a data-oriented expert reviews model output in a dashboard, scores it against criteria, and tracks performance over time.
That works brilliantly when one expert can objectively assess the output. What we've found with personalised products is that the reasons someone loves or doesn't love a gift are so varied as well as deeply embedded in personal and cultural context that you can't guess them. These personal and cultural rules are not captured most of the time; in fact, they are often subconscious to the giver and receiver. You often have to dig deep to get this rich context from the humans themselves. Evaluate from your own perspective and you quickly end up down a tunnel specific to your own context, with criteria that aren't diverse enough to be relevant to everyone.
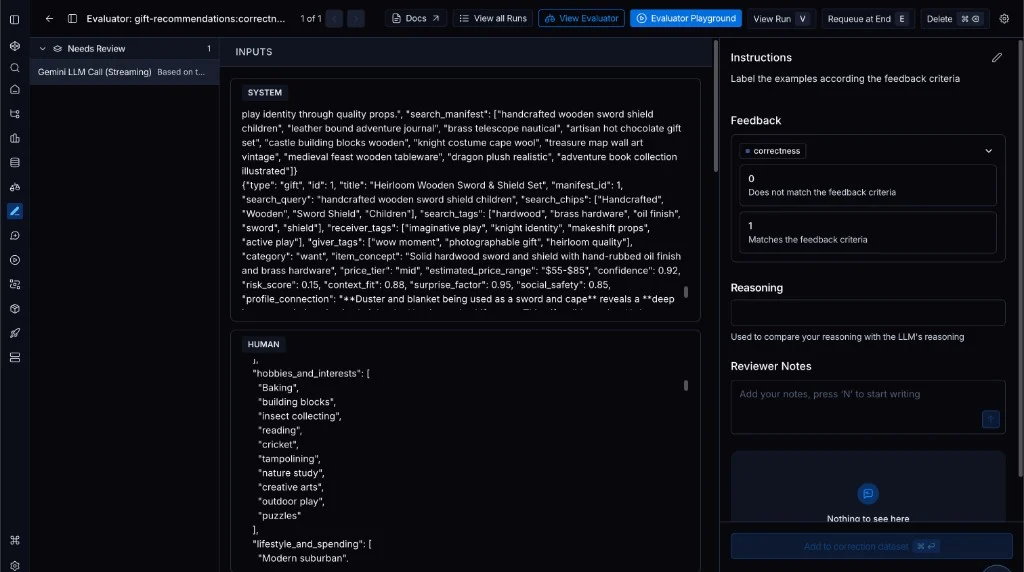
This is LangSmith's Evaluator Playground on a gift-recommendations run. On the left, the reviewer sees what went into the model: gift ideas in the system block and the recipient's hobbies in the human block. On the right, they score each output pass or fail against a correctness rubric one expert defined.
Powerful for objective quality scored by one expert. But personalisation requires subjective resonance scored by the actual user, in the product.
Want a deeper walkthrough of evals in LangSmith? Watch this overview on YouTube .
The tooling reinforces this gap. Dashboard-based evaluation happens in a technical interface, separate from the customer experience: scrolling panes inside panes, data tables, technical language. When your product is highly visual and the quality signal is emotional resonance, reviewing it in a whole bunch of text boxes strips the context that matters. One expert scoring from a dashboard can't represent millions of giver-receiver pairs. You need the actual users, in the actual product, reacting in the moment.
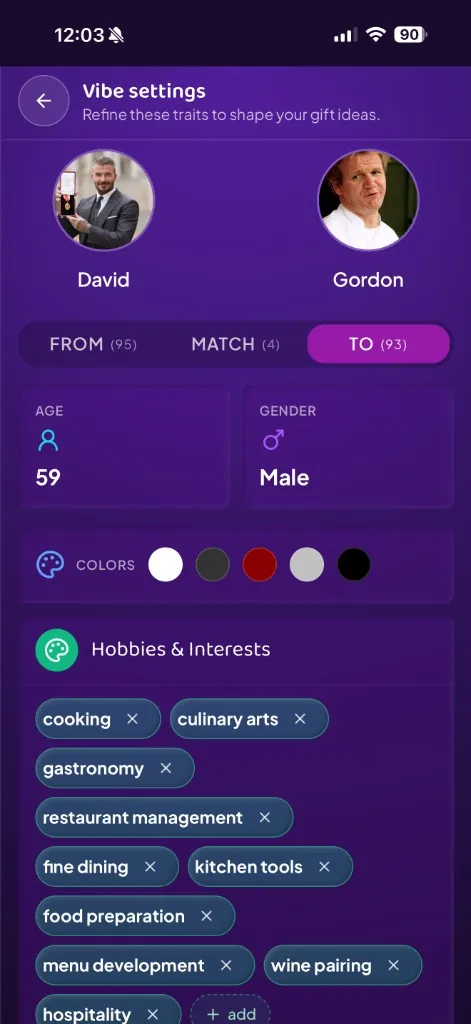
So our eval criteria had to account for both perspectives. Not just "would the receiver like this?" but "would the giver feel confident and proud handing this over?" We want the giver to feel like they've hit the jackpot. And we want the receiver to think: how did you know?
What we built
We looked at what existed. We wanted a tool that could capture user context in the moment, apply structured evaluation criteria, and work inside a consumer product rather than a data dashboard. Nothing did all three. Every option either pulled the evaluator out of the experience, reduced the signal to a numeric score, or required technical literacy from the participant. So we built it ourselves.
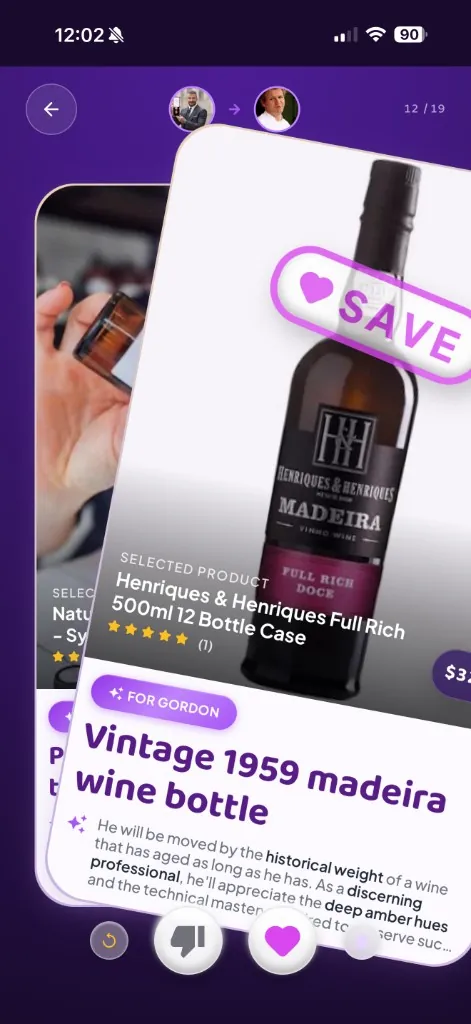
We built the evaluation directly into a labs mode of our product. Users see the same experience they'd normally see, with our evaluation checklist (our rubric rubric A structured checklist of roughly 50 pass/fail criteria across three layers: problems that fail a gift outright, wins that score what went spectacularly right, and set-level checks on variety and occasion fit. , detailed below) layered in. The key is that everything happens in the moment, in the actual experience, on the device they really use. No spreadsheets. No recall interviews days later. The response is captured while the feeling is fresh.
Research partner
We partnered with Uxbridge for the qualitative user research and eye tracking research. Having an external partner keeps the evaluation objective and stops us disappearing into our own assumptions.
Most of that signal is verbatim: we built microphone transcription into the flow so participants in user testing sessions can talk through their reaction in their own words, not just tap pass or fail. Those transcripts are pushed automatically into LangSmith, linked to the specific recommendation being scored. The interface was the easy part. The real investment is in the rubric, the interviews, and the dataset that trains the automated judge.
Step 1 · Turn on Labs
Step 2 · Swipe through ideas
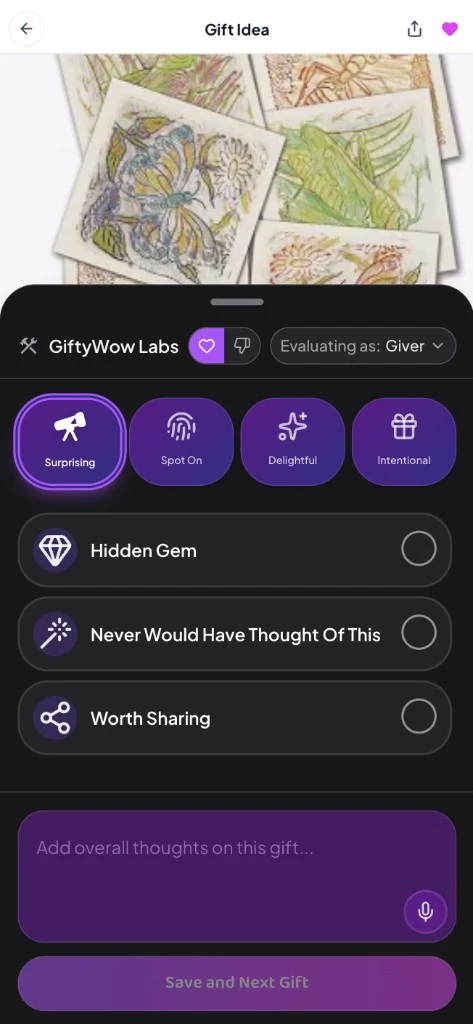
Step 3 · Give in-context feedback
One of the most revealing tests we run is having both the giver and the receiver score the same set. Seeing where their assessments diverge has been fascinating and directly backed up by gifting psychology research.
Here's an example of what this uncovers. We recommended a remote-controlled toy car as an Easter gift for a child. Seems reasonable. The parent rejected it. Why? In their family, Easter is a solemn holiday with religious significance. It's about new life and togetherness. Toys are fine, but they need to be things enjoyed together on the day. A toy car is a Christmas gift dropped into the wrong moment. You will never extract that from click data.
And then the insight goes straight to work. We took that learning and experimented with different ways to get gift ideas more suited to occasion context, building deeper understanding of what each occasion actually calls for into the prompts. Then we used the eval rubric to automatically review whether the new prompts improved or not. That cycle, from what users told us to prompt change to automated evaluation, is where the compounding happens.
The rubric
Through hundreds of hours of reviewing output and running user interviews, we built a proprietary evaluation rubric with roughly 50 items. Each item is pass or fail. No numeric scores. This keeps it objective, removes ambiguity, and makes it fast enough to use in a live interview.
The rubric works across three layers. The first catches problems: is this the wrong gift for this person, will it actually work, did the system think hard enough, and does the gift send the wrong message? Some problems are hard gates that fail the recommendation instantly. Others are weighted by severity.
The second layer measures wins. Most eval systems only track what went wrong. We also score what went spectacularly right: was it surprising, did it connect dots about this person, does the giver feel proud, does the receiver feel genuinely seen?
The third layer evaluates the set as a whole. Individual ideas might be fine, but if the mix lacks variety or doesn't fit the occasion, the experience still fails.
An overview of our rubric structure
-
Layer 1: Problems
Hard gates + weighted- Is this the wrong gift?
- Will it work?
- Did the system think hard enough?
- Does it send the wrong message?
Hard gates
Instant fail, no grey area
Weighted items
Scored by severity
-
Layer 2: Wins
The wow- Was it surprising?
- Did it connect dots about this person?
- Does the giver feel proud?
- Does the receiver feel seen?
-
Layer 3: Set review
The mix- Does the mix have variety?
- Does it fit the occasion?
Individual ideas might pass, but the set can still fail.
Layer 1 catches the objective failures, but the "why" behind each failure feeds the system forward. When users tell us in the moment why a gift missed, that structured reasoning updates the rubric itself, expands Layer 2 wins with new patterns we hadn't anticipated, and grows the training dataset the automated judge learns from. The gates are binary; the learning behind them is continuous.
From manual evaluation to automated assessment
Here's where it gets exciting. The human evaluation work was a deliberate, front-loaded investment to build something we couldn't get any other way: a proprietary dataset of thousands of evaluated recommendations with the reasoning behind every score.
That dataset now trains our automated LLM-as-a-judge system LLM-as-a-judge Using a large language model to evaluate the output of another model against defined criteria. The quality of the automated judge is only as good as the human data it learned from, which is why the structured evaluation investment matters. . The rubric was explicitly designed to teach an automated evaluator to assess recommendations at scale, without a human reviewing every one. Large language models are non-deterministic non-deterministic It's like giving a task to a team of five people. Every one comes back with something different. There's not one right answer and four wrong ones. They're all right and wrong in different ways. Same with large language models: the same input produces different outputs every time, and they can all be valid. That's why a pass/fail rubric trained on real human scores matters: it grounds the judge against observed preferences rather than letting it drift. : the same input can produce different valid outputs each time, which is why a pass/fail rubric trained on real human scores matters more than picking one "best" model.
The humans stay in the loop: validating automated scores, catching edge cases, and expanding the rubric as we encounter new contexts. The evaluation data feeds into LangSmith via API, so everything lives in one place and we can track performance using the tooling the industry already knows.
Currently, our evaluations predict actual user swipe behaviour at between 65 and 85 per cent accuracy. That number keeps climbing as we understand more precisely what "good" means for each combination of giver, receiver, and occasion.
What we've codified
What we've built is, at its core, a way to codify the 'Wow!' in gift giving. We've taken something that felt unmeasurable, the deeply personal, deeply subjective experience of receiving a gift that makes you feel genuinely known, and turned it into a structured, automated system that gets better with every cycle.
The new generation of products are really data products that harness large language models to create and curate valuable, useful, scalable data. The proprietary evaluation dataset we've built is exactly that. It's something no competitor can shortcut, and it compounds over time.
We built GiftyWow because we believe every gift-giving moment is an opportunity to surprise, delight, and deepen a connection between two people, and that opportunity should be accessible to everyone, not just the people who have hours to spend or a personal shopper on speed dial. This evaluation framework is how we measure whether we're actually delivering on that promise.
Frequently asked questions
What's actually in the GiftyWow evaluation rubric?
Think of it like a capability rubric for a person, except instead of evaluating whether a product manager is performing well, we're evaluating whether a gift recommendation is performing well.
A PM capability framework, like Brainmates' Product Capability Assessment, which evaluates 24 capabilities across strategy, execution, market focus, and solution development, breaks complex performance into structured, assessable dimensions. Ours does the same for gifts. Instead of "Does this PM identify the right problem before jumping to solutions? Pass or fail," we ask things like "Does this gift match the emotional register of the occasion? Pass or fail." Both are binary, both require judgement, and both are designed so you can train someone (or something) to apply them consistently at scale.
The rubric has roughly 50 items across three layers. Layer 1 catches problems: wrong category for the occasion, price mismatch with the recipient's world, a gift that sends an unintended message, or an item that simply won't work in this person's life. Some problems are hard gates that fail the recommendation instantly. Others are weighted by severity.
Layer 2 scores wins: did the recommendation surprise in a good way, does it connect dots about the person that only a close observer would notice, would the giver feel proud handing it over, does the receiver feel genuinely seen? We track wins because most eval systems only measure what went wrong, and that gives you a ceiling of "not bad" rather than a floor of "genuinely delightful."
Layer 3 evaluates the set: even if every individual gift scores well, if the mix lacks variety, leans too heavily on one category, or misreads the occasion's emotional register, the experience still fails.
Here's one real example from Layer 1: "If the gift idea specifies a physical attribute (egg-shaped, a specific colour, a named material), does the matched product actually have that attribute? Pass or fail." Sounds obvious. In practice, a system can generate a beautiful egg-themed Easter gift concept and then match it to a product that has nothing to do with eggs. Binary check. Hard gate. Fail.
What does "65-85% accuracy predicting swipe behaviour" actually mean?
When our automated evaluator reviews a recommendation and predicts pass or fail, it agrees with real users' actual swipe decisions (like or dislike, in the live product) between 65 and 85 percent of the time. The range depends on context: familiar occasion-relationship pairings sit at the higher end because we have more training data; novel or culturally specific pairings sit lower because the patterns are still emerging. The number keeps climbing as the training dataset grows. Every Labs session, every verbatim transcription, and every scored giver-receiver pair adds structured reasoning the judge can learn from.
When the giver and receiver disagree, what does GiftyWow recommend?
Both matter, and the product handles them as separate constraints, not a single averaged score. The receiver profile determines fit: does this gift belong in their world, match their aesthetic, land at the right price level, and connect to their actual interests? The giver profile determines pride: would this person feel confident and excited handing this over, or would they hesitate? When those two profiles are far apart, the system looks for the overlap: gifts the receiver will genuinely love that the giver can also feel proud giving. It doesn't default to the receiver's taste alone, because a gift the giver feels weird about rarely gets given with the energy that makes it land. And it doesn't default to the giver's taste, because that's how you end up giving aspirational gifts that feel like a lecture.
How does Labs feedback reach production recommendations?
The cycle works in three stages.
Stage 1: Capture. A user in Labs mode swipes through recommendations in the normal product experience. At each card, they can tap pass or fail against rubric criteria and, in research sessions, talk through their reaction via microphone transcription. Those structured scores and verbatim transcripts are pushed into LangSmith, tagged to the specific recommendation, the user's giver/receiver profiles, and the occasion.
Stage 2: Diagnose. The team reviews divergence patterns: where did the automated judge predict a win but the user said fail, or vice versa? The verbatims tell us why. We unpack each example to understand what went wrong and where in the system the fix lives. Sometimes it's a prompt change. Sometimes it's a platform change. Sometimes it's an experience change. And sometimes the evaluation engine itself got it wrong because it took a training example too literally and over-applied it.
A real example: an Easter gift idea was egg-themed. The concept was good. But the product we matched to it didn't have an egg anywhere. The fix wasn't to the idea generation or to the rubric. It was to the product-matching step: for certain contexts, we now do a hard match against specific keywords so the product actually represents the concept.
Stage 3: Ship. Fixes can go live same day. Sometimes within minutes. We then test the two variants against each other in market as an A/B experiment: did the change actually improve swipe behaviour, or did it just look better to us internally? If the new version doesn't outperform, it doesn't stay.
Why would GiftyWow be better than ChatGPT or Gemini for finding a gift?
The obvious counter-argument: Google already has your search history, your photos, your calendar, your location. Why can't Gemini just do this? And ChatGPT is genuinely good at generating ideas. So what's the moat?
First: general intelligence is not specialised expertise. ChatGPT and Gemini are extraordinary at synthesising what already exists on the internet. Ask for gift ideas and you'll get a competent summary of what gift blogs, Reddit threads, and retailer pages already say. The output is plausible, fast, and free. But it's a remix of existing content, not original thinking. What we need to do is come up with new, original gift ideas that are a mix of who this person is, who the giver is, what the occasion calls for, what's available right now, and what thousands of similar pairings have actually loved. That requires specialised approaches, specialised data, and specialised knowledge that a general model doesn't have and isn't tuned to produce.
Second: detailed tuning compounds. The value isn't in any single part of the system. It's in the detailed tuning of all the parts working together: how we profile from photos, how we generate concepts, how we match to real products, how we score quality, how we rank for this specific giver-receiver pair, and how we learn from what users actually do. Every Labs session, every verbatim, and every A/B result tightens something specific. That creates a growing pool of good-quality ideas and a system that gets measurably better at knowing what "good" means for each combination. A general model can't accumulate that kind of domain-specific learning because it's optimising for everything at once, not for this one deeply personal problem.
What are evals?
Think of them like performance reviews for AI systems. You have criteria for what success looks like. Good criteria help you make consistent judgements and track improvement. Evals do this for AI: structured ways to measure whether output is getting better or worse so you can compare versions. At their core, they answer three questions: is the quality high enough, are the results consistent and reliable, and did this change actually help?
What's LLM-as-a-judge?
Using a large language model to evaluate the output of another model against defined criteria. The quality of the automated judge is only as good as the human data it learned from, which is why the structured evaluation investment matters.
What does non-deterministic mean?
It's like giving a task to a team of five people. Every one comes back with something different. There's not one right answer and four wrong ones. They're all right and wrong in different ways. Same with large language models: the same input produces different outputs every time, and they can all be valid. That's why a pass/fail rubric trained on real human scores matters: it grounds the judge against observed preferences rather than letting it drift.
Which model is best for evals?
We've found the model matters less than the structure of the rubric. The simpler and clearer each criterion is, with plain explanations of what pass and fail look like, the broader the range of models that can judge reliably without drifting into vague praise or hallucinated scores.
Try GiftyWow for your next gift and tell us what you think. Feedback in the app helps us keep tuning what "good" means for every giver-receiver pair, and every cycle makes the recommendations sharper.
This is the first article in How we build, a series about what we're learning building GiftyWow. If something here resonated or you've solved this differently, we'd genuinely like to hear about it.